在人工智能(AI)迅猛发展的时代,一个新兴职业正悄然崛起,成为连接冰冷算法与温暖人类世界的桥梁——他们就是人工智能训练师。他们的核心工作,正是用海量数据‘喂养’AI模型,通过精心的‘教导’,让机器学会理解、模拟并服务于人类。而在这个过程中,公开、多元、高质量的公共数据扮演着至关重要的角色,是训练出更‘人性化’、更‘懂你’的AI的关键养分。
一、 人工智能训练师:AI的‘人类导师’
人工智能训练师并非简单地投喂数据,他们是一群集数据标注、模型调优、效果评估于一身的复合型人才。其工作流程可以概括为:
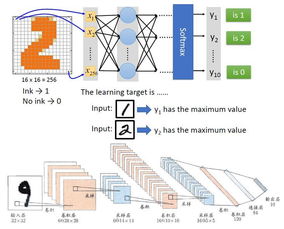
- 数据准备与标注:这是训练的基础。训练师需要根据AI要完成的任务(如图像识别、语音交互、文本理解),收集并处理大量原始数据。例如,为了让AI识别猫,他们需要准备成千上万张包含猫的图片,并手动或利用工具精确标注出图片中‘猫’的位置和类别。这个步骤决定了AI学习的‘教材’质量。
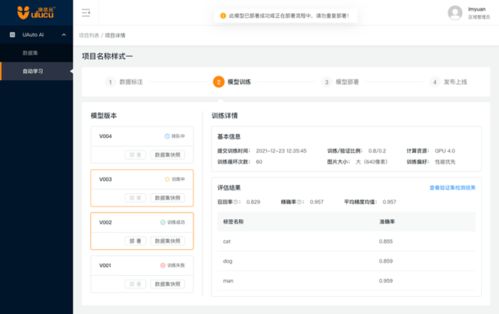
- 模型训练与调参:将标注好的数据‘喂’给机器学习模型。训练师需要选择合适的算法,设置学习率、迭代次数等参数,并监控训练过程,防止模型‘学偏’(过拟合)或‘没学会’(欠拟合)。
- 测试与优化:用未参与训练的新数据测试AI的表现,评估其准确率、响应速度等指标。根据测试结果,训练师需要分析错误案例,返回调整数据或模型参数,进行迭代优化,直到AI达到预期的智能水平。
他们的目标,是让AI的‘思考’和‘反应’尽可能贴近人类的逻辑与需求。
二、 公共数据:不可或缺的‘营养基’
如果说算法是AI的大脑结构,那么数据就是塑造其思维和认知的‘食物’。而人工智能公共数据——即由政府、科研机构、企业等公开释放的,可供合法获取和使用的数据资源——对于训练出公平、普惠、强大的AI至关重要。
- 规模与多样性:单个组织拥有的数据往往是片面和有限的。公共数据集合了来自社会方方面面的信息,涵盖了更广泛的人群、地域、场景和文化。用这样的数据训练AI,能有效避免模型产生偏见(例如,只认识特定肤色的人脸),使其具备更强的泛化能力和包容性,真正‘更懂’全体人类。
- 降低创新门槛:高质量的标注公共数据集(如ImageNet用于计算机视觉,Common Crawl用于自然语言处理)为高校、初创公司乃至个人开发者提供了宝贵的研发资源。这极大地降低了AI研发的成本和门槛,推动了整个生态的创新与繁荣。
- 促进公平与透明:在公共监督下采集和开放的基准数据集,可以作为衡量不同AI模型性能的‘标尺’,促进技术发展的公平竞赛。基于公共数据训练的模型,其决策逻辑也更有机会被检验和解释,有助于增加AI的透明度和可信度。
三、 挑战与未来:迈向更智慧的‘共育’
尽管前景广阔,但用数据‘喂养’AI的道路仍面临挑战:
- 数据质量与偏见:公共数据本身可能包含社会既有偏见或不准确信息,需训练师具备高度的伦理意识进行清洗和校正。
- 隐私与安全:在利用公共数据时,必须严格遵守法律法规,做好脱敏处理,保护个人隐私和数据安全。
- 场景化与专业化:通用数据难以满足医疗、法律、工业等垂直领域的深度需求,需要更多高质量、精细标注的行业公共数据出现。
人工智能训练师的角色将更加重要且复杂。他们不仅是技术专家,还需是伦理学家、社会观察家。而构建一个更加开放、协作、规范的公共数据生态,鼓励政府、企业、研究机构共享更多脱敏后的高质量数据,将是培养出真正理解人类、服务人类、与人类和谐共处的下一代AI的必由之路。通过人类训练师的智慧与公共数据的滋养,我们正在共同‘培育’一个更智能、更友好的数字未来。